Z-test
Z-test je statistický test, při němž za předpokladu nulové hypotézy má testová statistika normální rozdělení se známou směrodatnou odchylkou. Pokud směrodatnou odchylku předem neznáme, ale odhadujeme z dat, tak se používá Studentův t-test, leda by počet pozorování byl tak velký (udává se aspoň 30), že rozdíl mezi oběma typy testu je prakticky zanedbatelný.
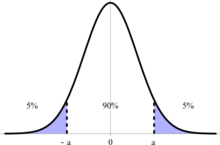
Postup testování z-testem je takový, že testovou statistiku lineární transformací standardizujeme a porovnáme s kritickou hodnotou, zde tedy vhodným kvantilem standardizovaného normálního rozdělení, vypočteným na základě požadované hladiny spolehlivosti. Pokud hodnota padne příliš daleko od nuly, tedy do „chvostu“ rozdělení za kritickou hodnotu, tak nulovou hypotézu zamítneme, v opačném případě nezamítneme.
Z-test obvykle vychází z předpokladu, že máme k dispozici nezávislých realizací náhodné veličiny , o které předpokládáme, že platí-li nulová hypotéza, mají normální rozdělení se středem a směrodatnou odchylkou . Jejich aritmetický průměr





proto má také normální rozdělení se středem a standardní chybou .

Lineární transformací uvedeného aritmetického průměru dostaneme veličinu

která má za předpokladu nulové hypotézy standardizované normální rozdělení a používá se jako testová statistika.
Z-test lze použít i pro testování velikosti rozdílu mezi středními hodnotami dvou normálních náhodných veličin se známými směrodatnými odchylkami. Mám-li vedle již popsané řady pozorování ještě další nezávislé realizace náhodné veličiny se střední hodnotou , směrodatnou odchylkou a aritmetickým průměrem




jež jsou navíc nezávislé na tak je normálně rozdělena se střední hodnotou a směrodatnou odchylkou . Testovací statistika pak je





a má opět standardizované normální rozdělení.
 | Tento článek je příliš stručný nebo postrádá důležité informace. Pomozte Wikipedii tím, že jej vhodně rozšíříte. Nevkládejte však bez oprávnění cizí texty. |









